I forget what book it was that I read but it made this very obvious statement about source code being a 2D grid. And this is very apparent with the whole row column cursor tracer shown in editors and in compiler errors. For some reason I always perceived these things as having significance on a per line basis and once I read that code is a fundamentally 2D entity it empowered me to create relationships along the vertical with judicious usage of vertical alignment and creating vertical harmony in my code. It’s pretty cool to perceive monospace fonts as allowing a lattice of 2D characters. There’s a trade off of course with unnecessary vertical white space in that readability is boosted but the lexer has more characters to ignore.
There was one numerical project I worked on where I had these _x and _y suffixes showing up very frequently in identifiers. Having the code vertically aligned actually made spotting copy paste bugs very easy because you can trace the vertical and find all _x’s lumped together or whatever the case may be. Inconsistencies stood out more readily I want to say.
One thing I try to do with the visual aspect of my code is to organize things semantically when possible with a good clear comment that tersely covers the operation: initialize abc, validate xyz, calculate, compute, guard clause: ignore case 1, load config, override X, etc
In The Beginning (tm) source code was very explicitly a 2D grid, with column numbers being lexically significant in both FORTRAN and COBOL because columns matter in punch card representation.
Of course, as every Lisp programmer knows, programs represented in almost any high-level language are actually trees, and to force them into a 2D grid of symbols is rather unnatural and awkward. Specifically, almost all 2D grids of symbols are lexically or syntactically invalid programs, and many natural source code transformations require either manual labor or special support from the editor.
There's at least one more readability error here that wasn't corrected. The email fields were declared in the order To, From, Subject, Body, but then From and To are swapped when they are added to the MIME message. This breaks parallelism.
100% agree. These optimizations in readability help a lot. Also, a failure to optimize code for readability makes reading code difficult. I once read some code where I immediately concluded that something was wrong because a function was being called from the wrong method. Turned out that it actually was in the right method but there was no vertical space between two methods giving the wrong impression of where that particular method call actually was. I feel quite alone with this opinion though. I see messy code all around me. One particular thing that everybody seems to agree on but that is pretty much objectively bad is the common way to line up lambdas. People do
The 'broken lambda' that one tends to see everywhere is driving me nuts.
The principle is that code already should give the right impression of what is going on at the first glance. Another thing that is quite a spectacular failure in this regard is the google style guide. The indents of 2 tabs combined with braces that do not line up must have been optimized to be as unreadable as possible.
I've occasionally fantasized about a code editor that doesn't allow scrolling, so you're forced to break code up in to pieces that fit on a single screen. I think that would greatly improve readability.
That would also help with one of the main arguments against "visual" programming languages - they get too hard to read as programs get larger. Simply don't allow scrolling or zooming the source.
The idea that visual programming languages get too hard to read as programs get larger doesn't really resonate with me.
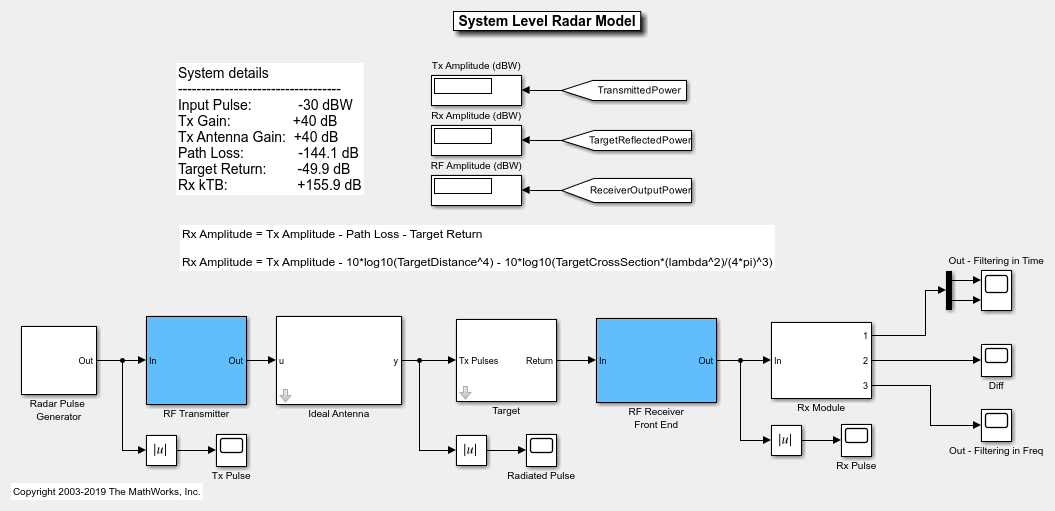
Just like written code, you need to create higher level abstractions. In simulink for example, you might have 1 top level box called a "Radar". You drill down into that, and find lower level components like an RF transmitter, but still those are abstractions that you can drill down into [0]
Yes if you squeezed all low level implementation onto one screen it'd be hard to read, but same as if you put all low level c code in one giant file without any abstractions.
I agree! However often you see arguments against visual programming languages where they show a screenshot that looks like a giant mess with tons of stuff in it. My point is if the editor didn't allow scrolling or zooming that would force the developer to break things down in to components as you describe.
While I admire the intent, I can definitely see bad developers simply writing long functions in multiple "parts" to get around the system.
public void shittyLongFunctionPart1(...) { //First line of screen 1
..
..
shittyLongFunctionPart2(...);
}//last line of screen 1
public void shittyLongFunctionPart2(...) { //First line of screen 2
..
..
shittyLongFunctionPart3(...);
}//last line of screen 2
Yet another example of culture trumping process. At the end of the day you need developers who give enough of a shit about their craft to write readable/testable/maintainable code. And that sucks because it seems relatively rare.
It does not matter. However hard you "prefer" the value of pi to be 3, it will stay an irrational number. Eight-space tabs are a constant of the universe.
not in this universe they aren't - many popular applications indent 4 spaces by default when pressing the Tab key, and render physical tabs as four spaces, for example github ;)
tabs of 8 space width are a legacy travesty that wastes space :)
Ours is indeed a decadent universe that is slowly being corrupted by powerful forces of evil (such as the 4-space tab brain damage of github). But there are still beacons of light to guide us:
That doesn't do anything to reduce the complexity of code, it just means you have a lot more functions to read and the actual logical units distributed across random sets of them to fit the arbitrary line limit. Some of the worst codebases I've ever seen had many small functions because the logical boundaries of the problem domain didn't match the logical boundaries of the source code.
Wow, this article does such a good job of concisely explaining these concepts I've been trying to put into words for so long! Definitely going to be sharing with some of the juniors.
> Wow, this article does such a good job of concisely explaining these concepts ... Definitely going to be sharing with some of the juniors.
Not sure this is the type of article for juniors. I don't think it's really a handbook for writing more pleasing code. It's more a statement, that the way we structure and style our code is a design decision. Code's visual design is an area that many programming languages have experimented with mostly over trial and error, but it's not something that is well studied.
New programming languages come out all the time, and they often tout advantages such as speed or security, but they rarely try to justify design decisions based on visual design and readability. It seems like a ripe field to dive deeper into.
The article focused on the surface level of code, which I think is important. But the next level is where you can apply the same principles to the class hierarchy or how data flows.
That's how I keep them -- e.g. different number of line breaks between different items (e.g. 2 lines between import statements and class definition, but 1 line between methods inside the class).
That's too crude. What I'm saying is, it should be around 0.5 line height for grouping inside a method, ~1-1.2 between items of a class, 2-2.5 around classes.
Of course, coders' tendency to nest breaks the idea a bit on levels deeper than a method. Though I think with a lot of fiddling some variation can still be achieved.
Absolutely! I would say 90% isn't high enough when you consider the amount of time reviewing pull requests on a large team. Add to that the reading required when deciding on an external library (yes, some people simply use only popularity metrics and Github repo signals like number of issues etc. Fair enough. Our team tries to skim the entire code at least once.)
We also do team code reviews on a big screen over pizza twice a month. It gives a chance for the entire team to learn something new without being under pressure. So yea, lots of reading happens around here. The side-effect is some pretty good (and readable) code IMHO.
Overall, the readability is good. My only complaint is the terse variable names, which makes the more complex methods more time consuming to follow (because you have to keep going back to refer to their definitions to remember what they are). For example, https://github.com/golang/go/blob/master/src/encoding/json/e...
The variable naming scheme in that code is incredibly consistent with respect to type. That should alleviate some of the problems, and I think the code would be more annoying to read if the variable names weren’t terse (like Simonyi Hungarian).
When you dive into the code, especially at the point I chose, you are presented with:
e.string(kv.s, opts.escapeHTML)
And so, you have the following questions: What is e? What is kv? What is s in kv? To answer these, you have to scan upwards. e is encodeState. OK, not too bad. kv is maybe key-value of something? it comes from sv (string value maybe?), which comes from:
sv := make([]reflectWithString, len(keys))
So a string value? Or a list of string keys? A list of structs, OK. s might be a string value inside, which has ... some meaning I guess? Digging around, I see it defined as:
type reflectWithString struct {
v reflect.Value
s string
}
So it is a string, but I still don't know what its purpose is. After a bunch of digging around to see how it's used, it looks like s is a string representation of the value, but I'd need to look over more code to be 100% sure.
Now I know what this calling string() on the encoder state, using the string representation of the key value. "string" is still a bit cryptic. It could be renamed. Looking inside "string" I see that it's writing things, so maybe a better name is:
With this version, I know without having to look at any other lines that this code is supposed to write the string representation of a key value to the encoder state, doing HTML escapes. I don't need to look inside the guts of anything to figure this out. I don't even have to leave this line.
Type is purpose. And anyways, the English alternatives are still vague and aren’t really improvements. KV is incredibly standard, even in English conversations (KV store is said more often than key value store). E is not descriptive, but neither is encodeState (WTF does that even mean?). S is a perfect abbreviation for a generic string, calling it string instead isn’t much better, really! It’s obvious in this case that it is only meant to be a generic string (what else could be meant by reflectWithString?).
I do prefer method names to be descriptive, so verbs are nice. Well, unless we are dealing with very generic lambda code, then there might not be better options beyond f, g, and p.
Also, as a rule of thumb: the more rarely something is used, the more descriptive its name needs to be. If something is used often in some code, terseness is more forgivable and even desirable in many cases.
A great example of this is "i" as a standard indexer, or "x" and "y" as horizontal and vertical coordinates. They are used often therefore terseness can be applied and is useful. Also why "KV" is often used to be mean key-value, the concept is just very pervasive. The terseness for variable names in the linked to code seems more acceptable because those variables of consistency and repeated usage.
The consistency/types help a lot, but I would rather read 'destination' instead of 'dst', 'value' instead of 'v' etc in methods or blocks that are more than 2-3 lines. I don't want to have to guess or think about what the variable is supposed to be about.
I actually feel like this would hinder readability, since we should be trying to read it like code rather than English. Destination is just as vague to me as dst, ditto for value and v, and I don’t have to move my eyes as much horizontally to read a line of code, not to mention that more verbose makes would sacrifice readability of the algorithmic structure for more context that quickly becomes redundant.
Writing code is generally much easier than reading it. Additionally, once you write code, you usually end up needing to change or maintain it. 90% is not uncommon.
It's also generally a good sign if you spend less time writing code, because the hard part is usually in the design/planning phase of a new system or product. Days of programming saves hours of planning.
For personal side projects, I spend at least 80% of my time thinking about the code that I'm going to write, 5% writing it and 15% reading it.
The more experienced I become, the less time I spend writing code and the more time I spend thinking about it and drawing diagrams on paper.
Coding should not be the bottleneck. The bottleneck should be deciding what solution to choose because there are usually a lot of factors to consider and it takes a while to identify all the main ones. It's not unusual for me to spend multiple days just thinking through different technical solutions without writing any code.
IMO developers who commit often and too many lines are juniors. Most of these lines will have to be rewritten because there wasn't enough thought behind them.
Coding is also a way of thinking. Too much planning up front also has a name (water fall?), the other option is to write now to get understanding and rewrite later as that understanding accumulates (I think that way if working has a name also).
Of course, there are many kinds of valid working styles in between. I personally would rather see juniors write, make mistakes, and rewrite than just be paralyzed with thought/planning anxiety, which is perhaps more effective for more experienced developers.
You don't necessarily need to plan everything up front. You can identify critical decisions points within your project as you go along. Personally, I try to keep interfaces between modules as simple and restrictive as possible (as simple as they can be while still meeting business requirements) but I keep the option open to add more flexibility/complexity later if it turns out to be absolutely necessary. Often it turns out to not be necessary. Having simple and restrictive module interfaces is extremely valuable if you can figure out what the right restrictions are.
I like to plan by coding prototypes. It depends on the task at hand, but for certain problems it can be nice to create a new branch or repo even and test out my ideas. I'll often write sketches on my phone too.
Yes, for better or for worse. I deal with a very complex system in my daily work, and I'm often (a dozen or more times each week) tasked with answering questions along the lines of "Why did this happen?" or "What would the system do if (something) were to happen?"
Being a mere moral, I must consult the code to find an answer.
I think it's "worse" than that. Last week, I wrote four classes. They weren't very long. I spent most of the time trawling through libraries I was using trying to figure out how to write those four classes.
But it felt like quite a productive week: they were the "right" four classes, and I could have written a lot more code that did the job less concisely.
Yes. Even by being a solo developer for quite some time, I ended up spending about that amount of time reading code, with a good portion being spent reading my own old code.
It's been a ramp up of course, starting with a totally blank codebase, I started with 100% of time "writing" code (quotes meaning : thinking about and then actually writing, I assume it goes together).
In any maintenance-mode organisation that's the reality for everyone. As is spending increasingly large chunks of time that result in almost no lines of code being committed, because you're debugging more and more complex problems. Two weeks to find a stray minus sign. Four weeks to change some numbers in a table. Another month to determine a PCB change is needed. That kind of thing.
(We could do with a serious version of "thedailywtf" for interesting debugging stories, I think it would open a few eyes)
The general rule is that of the time you spend with code, 90% is reading and 10% is writing.
This does not mean that 90% of your time is spend reading code. There are other tasks that programmers do during their day.
I would say that the 90% number sounds roughly true for me. And probably I read my own code somewhat less than that, but spend more time reading others’ code, either due to code reviews or just to understand things before making changes to existing systems.
{kind=link}
There was one numerical project I worked on where I had these _x and _y suffixes showing up very frequently in identifiers. Having the code vertically aligned actually made spotting copy paste bugs very easy because you can trace the vertical and find all _x’s lumped together or whatever the case may be. Inconsistencies stood out more readily I want to say.
One thing I try to do with the visual aspect of my code is to organize things semantically when possible with a good clear comment that tersely covers the operation: initialize abc, validate xyz, calculate, compute, guard clause: ignore case 1, load config, override X, etc