Afaik it's a custom system with download-and-cache-on-demand.
Note that there's nothing forbidding you from writing a virtual git filesystem that fetches objects from some centralized repo as files are open()ed. Git on cloud steroids.
What bothers me is that they did not responsibly disclose the vulnerabilities to the manufacturers ahead of time. This is not moral, and I'm not sure what one gains by not doing that. I think that conference organizers should pressure presenters to do that before talks.
Either that or attendees should apply bottom up pressure and ask live questions like "what did you do to responsibly disclose this issue?". I think I'll do that on future security conferences I attend.
I wish the everyone would stop using the term "responsible" to describe "coordinated" disclosure. Researchers do not owe vendors any cooperation at all. It is perfectly moral to present factual information without any notice whatsoever. I think there's often something to gain through coordinated disclosure, but not always, and it's not your choice to make unless we're talking about your own findings.
It's not about the companies. I do not care much about them.
It's about people that may be hacked between someone's 0day disclosure and manufacturer's response. And if the manufacturer doesn't care to fix the bug - roast them about that. It's their fault.
It's not moral because people (not companies) may suffer. Your actions have consequences.
Yes but why not send a single email to the manufacturer before making it public? Does it really hurt so much?
From a "cyberpunk hacker" mentality this only gives you an opportunity to roast the manufacturer if they do nothing. Perhaps even bankrupt them, I don't care. Competition will take their places and hopefully be better.
Potentially yes. The manufacturer may attempt to prevent publication through legal threats or action, which can be annoying and expensive even if you ultimately win. The incentive to be annoying goes down significantly once the disclosure cannot be prevented (because it's already public) and the public is watching (i.e. any action against the researcher has a higher likelihood of public backlash).
It also allows the manufacturer, who is likely more experienced and has more resources, to start PR to downplay the attack.
I generally default to responsible/coordinated disclosure, but I also do my research first. If the company has previously shown undesirable behavior (like the stuff I've described), or I've reported to them previously and didn't like the experience, they'll learn about the disclosure from the news.
It's like finding out my neighbor doesn't lock his front door at night and announcing it on twitter. I didn't create the vulnerability but I'm helping criminals take advantage of it.
>It's like finding out my neighbor doesn't lock his front door at night and announcing it on twitter.
No, it's like finding out your neighbor sold a bunch of faulty locks to a bunch of other people. There's a difference between information that would benefit only one person (the neighbor in your analogy) and information that would benefit many people (the neighbor's customers in my analogy)
In that case it would be better to inform future customers so they don't buy the faulty lock, rather than throwing together an in-depth tutorial on how to take advantage of the lock. Especially since, unlike a lock, software can be updated to fix the problem.
"There's a known exploit that has yet to be fixed"
But then there's an issue of trust. Without documenting the exploit to the public I suppose no one would believe you.
Nevertheless the consequence of releasing an exploit to the public is that you've also informed nefarious players. Actually it's worse than that. Likely the nefarious players are the only ones paying any attention to stuff like this.
Perhaps what's needed is a trusted third party middleman who can verify an exploit exists without releasing it to the general public?
It's not the researchers responsibly that a vendor is incompetent, frankly. The vendor released something broken, that's their burden to bear, it's not wise to assume that you're the first to find a bug, with that in mind expedient full disclosure is acting with the customers best interests.
I've been doing security research in this industry for a while and it's effectively not worth anybodies time to attempt to report hardware wallet, or software bugs 'responsibly'. I've found that by far the most common responses are being told that the attack doesn't fit into their design (as here), it's not reasonable to expect, or that for some reason. For a long time the Trezor wallets custom crypto library was simply python transliterated and had a sidechannel attack so large that you could measure the EC multiply operation with a SDR from across a room. This was supposedly out of their scope (but has been since somewhat fixed, but not entirely) for some reason, despite being something that is easily fixed using industry standard constant time operations.
Responses you do get at protecting the fact that a lot of the bugs are burned into hardware and can't be fixed by anything but them re-issuing it. It's not in the interests to ever acknowledge issues.
Power analysis is a lot harder to fix then you think. Constant time isn't enough: you probably need blinding and some hardware assistance with features that are inevitably under NDA.
This is true. Many of these devices are using effectively joke crypto libraries however, theres a world of difference between something that needs a sophisticated setup, and the python crypto library that was transliterated into C and makes absolutely no effort at being constant time. The original Trezor software took something in the order of 300ms to produce a single signature. You could probably have done recovery of the nonce from ec multiply with a stopwatch.
If your security appliance is using an ECDSA library for Arduino that has absolutely zero tests or review, you just outright lost. Some of the more well known products in the space do exactly this.
I'd be interested. The two still offending tools (spell and f77) sound super rarely used these days. I think it's fair to compare samples of commonly used tools in 1995 with samples of commonly used tools in 2018 even if those samples are widely different. This would be more related to the change in the probability that an average user sees a crash.
This was on Ubuntu 14.04 -- I know 14.04 is dated, but its the last image I had running from the previous tests :).
I wrote some stupidly simple bash to just pipe output of fuzz to every executable in /usr/bin/, with a 10 second timeout. This was only meant as a quick experiment, so there was no consideration of proper arguments (e.g. some applications may only read files and not stdin).
often gets pulled in if other fortran (gfortran usually on a linux) is not available when building certain numerical software which in turn relies on netlib.org open fortran code, which in turn is written in fortran77
these libraries are give-or-take at the core of tons of numerical/scientific computing software, and likely used by many other programs needing heavy math
Translators are interesting here. In this case it looks like it's just falling during translation (and a fast failure at that). An interesting question would be if there were a structured input (ie; valid Fortran) that result in the emission of unsafe C.
Not downvoting as it’s still an interesting comment bringing personal insight.
This is an article about a different approach to detect/diagnose depression, and the first comment reads a lot like “this weird trick I used to beat depression”.
The “Not meaning to demean anyone's hard work with psychology, but” really doesn’t help. They found a way to beat their depression, what does it have to do with other people’s hard work in psychology ?
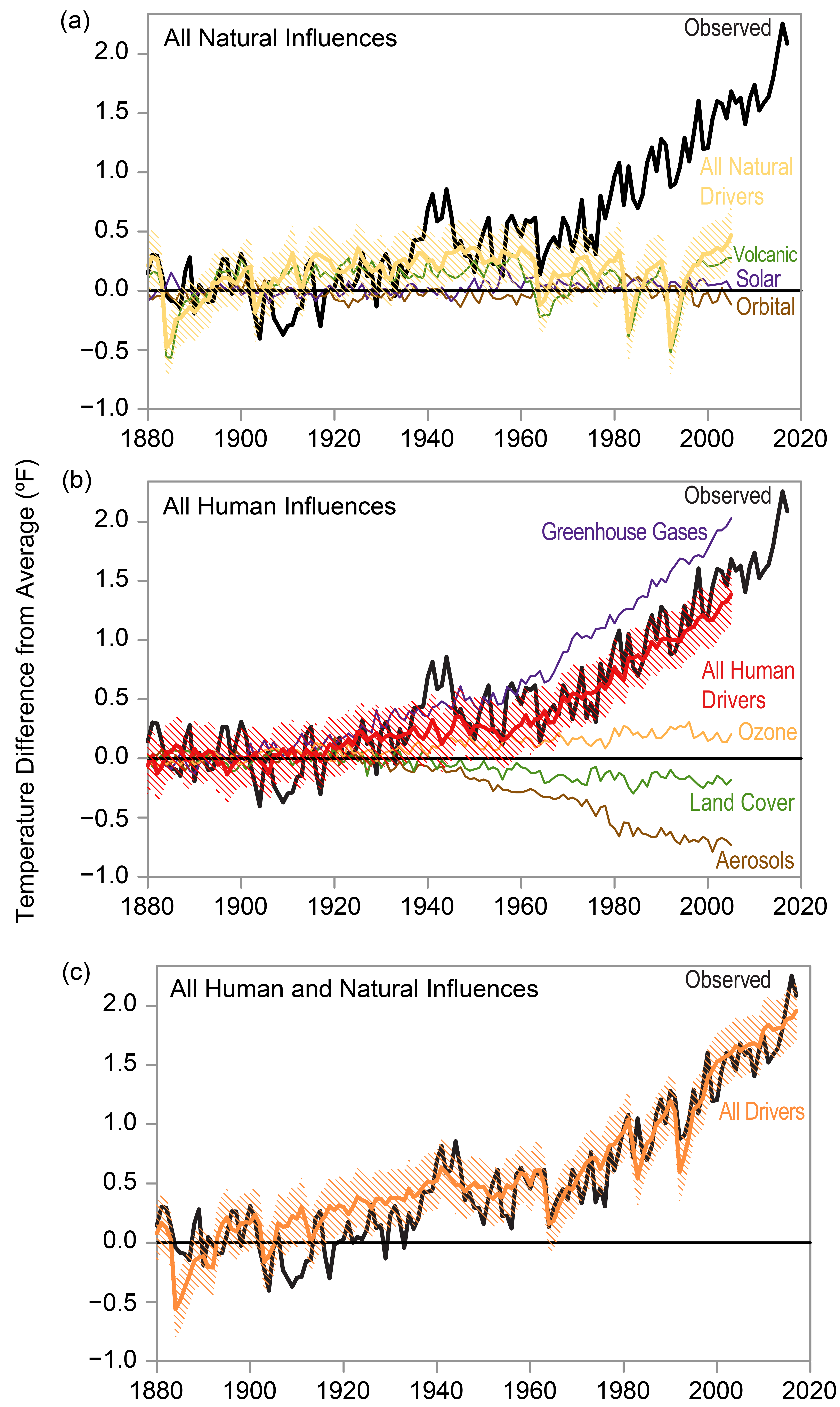
These took out much of the heat from greenhouse gasses. And in my opinion you either buy the climate change models (which are very aware of aerosols), or you don't. It doesn't make sense to believe that the planet will heat up more, that it is due to humans, but aerosols are not a part of the story.
Even if climate change is nonsense (it isn't) it still makes sense to get off energy sources that are known to destroy air quality. This should be common sense to anybody, who likes smog?
This said some of the talk that I've been hearing recently has me concerned for peoples' mental well being. I've heard numerous peers and coworkers in the past year express belief that they would not live long enough to have grandchildren because humanity will be extinct by then. That we have 20 years or less of life, that the situation is doomed, etc. None of this is a healthy mindset.
Yup, climate change is real - it's evident from computing average temperatures. No point in debating that.
I completely agree that smog is terrible and essentially kills people. My point was the really bad consequences of warming (mass migrations from deserted areas and subsequent refugee crises, wars over farmable land, exodus from flooded areas) can be avoided via aerosols.
But the source of the warming should be completely open for debate. I for one am looking at the sun as the source, starting with the sunspot maximum event of 1958 that sparked the US government to create Nasa.
Why is that a productive debate? Even if CO2 is not the source, we should still eliminate our reliance on the combustion of fossil fuels because those fuel sources still undeniably pollute our environment in other serious ways. The mining and burning of coal is bad for our environment even if CO2 was a non-issue.
For me, it's about the truth and I'm pretty tired of being dismissed because I dont agree with the anti-human narrative that's becoming the mainstream.
I don't get how you jumped to that last sentence. The way I read what you wrote is that we'd have been screwed earlier without aerosols, but that our current models account for them and still show us being screwed.
I'm asking why. Is there some reason for them not to open it? AMD are quite positive about opening up other things, like GPU drivers for example. So why not firmware as well?
In the GPU case I know the reason - it's the DRM garbage (HDCP and Co.). Support for DRM dictates for them to keep it closed. But even there, they could provide alternative firmware without DRM, and make it open. But for CPU, there is no real reason it seems.
I wish more people would publish data as SQLite databases (if the size permits, of course; usually it does). It's so much more reliable than CSVs, which have at least a few dimensions of significant differences (quoted/unquoted, comma vs semicolon vs tab vs space, headers/no headers, comments). Not to mention that initial data exploration can be done right in an SQLite explorer/browser tool.
I keep harping on about this at work - a sqlite file carries its schema with it so you can inspect it. With foreign keys, notnull, check and other constraints you can easily make out what the data is about. There is a driver in every language it seems, and if not the docs are very good so if you are handy with FFI it is easy to build one. It can be far more compact than XML (gulp! SOAP) with the equivalent amount of data as the amount of data gets larger. Being a single file, it can be sent over the wire like any other. And you use SQL to interface with it.
There's a fairly large ecosystem of tools for creating and processing financial data in XBRL which doesn't exist for SQLite. All the Big 4 handle XBRL already - I know because I write the software they use. It's quite straightforward to take a Word document, for example, and turn it into XBRL; we even use machine learning to automatically tag the tables.
I can easily imagine how painful it is for you to process XBRL from scratch, but it's not crazy to exploit the existing infrastructure.
Of course if you give a project to IBM I wouldn't be surprised if it costs a billion dollars, especially given they know roughly nothing about XBRL...
I'd never heard of XBRL, looks very interesting. It seems it's primarily used in financial reporting environments though. Is it suitable for general purpose reporting as well?
In principle yes, it was intended for general business reporting.
Essentially each filing (called an instance) consists of a series of 'facts', each of which reports a single value and some metadata, and footnotes, which are XHTML content attached to facts. Fact metadata includes dimensions, which can specify arbitrary properties of a fact. So a fact might be e.g. 'profit' with metadata declaring it's in 2018, in the UK, and on beer, but all of those aspects would be defined by a specific set of rules called a taxonomy. You can create a taxonomy for any form of reporting you want.
There's also a language, XBRL Formula, which allows taxonomies to define validation. It allows something semantically similar to SQL queries over the facts in an instance, with the resulting rows being fed into arbitrary XPath expressions.
Unfortunately the tools for working with XBRL are mostly quite expensive, which probably limits its application outside finance. Arelle is a free and fairly standards compliant tool that will parse, validate and render XBRL and even push the data into an SQL database, but it's written in Python and isn't very performant. (Although it's probably good enough for most uses since it's used as the backend for US XBRL filing.) I'm not sure if there are any open source tools to help with creating instances.
Also creating a taxonomy itself is quite challenging. There are (expensive) tools to help, and using them it's still quite challenging. For real-world taxonomies it usually involves a six or seven figure payment to one of the few companies with the right expertise.
XBRL is the format the SEC (security and exchange commission, the government "accountants of last resort" that check publicly traded companies). This means there's regular XBRL files (every quarter) for every large publicly traded US company.
Please do keep in mind that this is a sort of XML key-value database with a number of keys standardized, and some level of rules defined that say "if a bank lends Volkswagen money and it uses 12% of that money to Google to run ads with a repo clause, you enter add A to value X and B to value Y". In other words, there's rules that define how complex financial data is entered into those standardized values. To find those rules, there's a SEC textbook that you wouldn't wish on your worst enemy, nothing about that in the files themselves.
There's a large directory at the SEC with the quarterly XBRLs for all US publicly traded companies. Used to be accessible over FTP until a little over a year ago.
XBRL files exist for all forms to be filed with the SEC. The ones you probably want are the 10-Q and 10-K ones (q = quarterly, k = no idea, but somehow means yearly)
(of course there's an entire industry of accountants essentially about hacking those rules, and therefore the meaning of those files. So let me give you a free quick 5 year experience in financial analysis: search for "GAAP vs non-GAAP", read 2 articles, decide the conspiracy theorists are less informative than the government, and just believe the SEC is at least trying. That doesn't mean nobody's lying, but GAAP vs non-GAAP is generally not what they're lying about)
As much as I love SQLite, and while it is open source, it is a single implementation that AFAIK has no published open specification. The only way to read an SQLite file is using SQLite, and in that respect, it is for many users just as closed as wrapping something in a word document.
CSV isn't perfect, but it provides a ton of flexibility, for example, CSVs can be streamed or support parallel segmented download across a network with useful work possible during the transfer. The format is so simple that it can approach almost free to parse (see e.g. my own https://github.com/dw/csvmonkey ).
CSV is also distinguished in that regular home users with spreadsheet programs can usually do most things a developer can do with the same file. For me user empowerment trumps all other goals in software, including warts. Things like JSON, XML or SQLite definitely don't fit in that category, although I guess SQLite is at least better due to the wide availability of decent GUIs for it.
Finally as a data transfer format, SQLite has the potential to be massively inefficient. Done incorrectly it can ship useless indexes that can inflate size >100%, and even in the absence of those, depending on how amenable the data is to being stored in a btree and the access patterns used to insert it, can leave tons of wasted space inside the file, or AFAIK even chunks of previously deleted data.
>"As much as I love SQLite, and while it is open source, it is a single implementation that AFAIK has no published open specification. The only way to read an SQLite file is using SQLite, and in that respect, it is for many users just as closed as wrapping something in a word document."
That's an extreme position to take, particularly since the SQLite code is public domain. Furthermore it's one of the formats recommended by the Library of Congress for archival/data preservation:
> The only way to read an SQLite file is using SQLite
This part unfortunately isn't a position, it's absolute. It's hard to imagine a situation where as a developer we would not have access to a C runtime or for any reason whatsoever would not be able to use SQLite, but the hard dependency on its code is real, and represents a real hazard in the wrong environment. A super easy example would be parsing data on say, a tiny microcontroller on an IOT device. This can start to hurt quickly:
> Compiling with GCC and -Os results in a binary that is slightly less than 500KB in size
Open formats at least give you the option of implementing whatever minimal hack is necessary to finish your job without say, introducing some intermediary to do an upfront conversion, and at least for this reason SQLite cannot really be considered a perfectly universal format
>> The only way to read an SQLite file is using SQLite
> This part unfortunately isn't a position, it's absolute.
It's also false. I know of SQLJet which is a pure java implementation, there may be others. But in the end, the SQLite format being well defined and documented [1], a sure-fire way to read an SQLite file is writing the code to read an SQLite file.
Since SQLite a rock-solid, public domain, portable C library, it might not be the best idea to do that, but it is completely feasible. No one stops you from "implementing whatever minimal hack is necessary to finish your job" while using the SQLite format.
> A super easy example would be parsing data on say, a tiny microcontroller on an IOT device.
I mean, it's a point, but I don't think anybody is saying that SQLite should replace all data storage formats everywhere. If you're just storing a few dozen short text strings with keys, plain text is fine. I don't think you'd want to have a JSON parser on a tiny microcontroller either.
>"as closed as wrapping something in a word document."
Sure CVS makes it trivial to waste your time reinventing the wheel, making your own parser. The situations were there are technical limitations that prevent the use of sqlite are becoming vanishingly rare. (Not to mention the resources necessary to use sqlite is unrelated to how many implementations there are or whether it's 'open' or 'closed'.)
Do you have a source for that claim? Mozilla's 2010 justification for dropping WebSQL was that SQLite doesn't implement a particular standard of SQL (incidentally no SQL implementation does, SQL is notorious for that, every vendor implements something slightly different with parts of the various standards excluded and other features included.)
But more to the point, Mozilla's gripe was with SQLite's API, not with the file format used by SQLite. I can't find any source for the file format used by SQLite being the problem that tripped up WebSQL.
You argue bases on a good principle. But while the principle of open well documented standard is good one, it's just a principle. The goal is portability, consistence and long term stability.
When I open my data I usually publish both CSV dumps (for those who prefer using awk/sed and command line tools; this is usually easier) and MariaDB reconstructive files. I'll consider SQLite databases from now on, I like that idea.
That is a truly fantastic idea. Especially if Excel added file format support for it directly to open it within excel with a double click, one table per sheet within the workbook. I know, not the ideal way to use SQLite, but that would ensure easy adoption by the average person that doesn't have SQL or relational database knowledge. (And would allow them to get a bit of that relational knowledge via power query)
Some might think Access would be the more obvious choice, but for the average user Access is not an accessible tool (we don't even install it as part of the Office suite where I work) and they're much more comfortable in Excel.
I've probably said this around here before, but I wish people trade SQLite files instead of Excel workbooks. Excel (and the like) can operate on top of SQLite. This way we have data portability, data integrity, and ease of data access.
The problem is data corruption. If a CSV is corrupted, then I could at least parse part of the data. For a corrupted SQL file, I'm done. Also, diff is not working for binary format, and it is more difficult to trace change for SQL format.
What is the source of the corruption. Unlikely to be disks nowadays but people should take backups of things. Very unlikely to be a SQLite buggy write but again a backup could save you. Worse case I’m sure there are tools to recover a corrupted file.
Oh this goes way back. The first SSD drives from Hong Kong advertised double or quadruple their capacity - you didn't find out until you tried to write the N+1th block and it overwrote the 0th block. Back in the 90's?
It's not that CSV is hard to parse. It's that there's no guarantee that you'll get proper CSV. For example, it may literally be "CSV", without quotes. And that's fatal if values contain commas. I've even seen CSV with values that contain ``","``!
RFC4180 [1] standardizes CSV, but there are many implementations that don't read this 100% and unfortunately even more (including an extremely popular spreadsheet application) that don't write it.
If you are including CSV functionality in something you work on, please read and follow this (tiny) spec!
Whether Excel writes standard CSV or not depends on the user's locale settings. E.g. with a German locale you get a semicolon (;) as a separator which you can only change system-wide. However, apart from the changed seperator, it's still standard CSV, which still works with Python or SQLite (.separator ; .import foo.csv foo).
A bigger issue is that Excel tends to write large numbers in scientific notation, which is a common issue handling price lists. E.g. it'll turn EAN numbers into 6.2134e+11, losing most of the number. Then you have to go back to the XLS file and change the column type into text and exporting it again as CSV. As this is lossy you can't fix it when receiving such a file.
Something like the SQL Server Import/Export Wizard but being able to write SQLite files would be very handy.
The worst part about CSV is the locale-specific format used by some programs. For example when exporting to CSV a German Excel will use the comma as the decimal separator in numbers and a semicolon for the value separator. So you need to specify the exact format for each individual file you want to import.
Back when I worked at an NLP company, my boss used to say that he was "morally opposed to CSV".
When sharing tabular data in text format, he always preferred TSV because commas were everywhere in the material we were working with, but tab characters were really rare.
I've always been curious about the characters in ASCII for this, but I've never seen them used in the wild. Stuff like "Group Separator" (0x1D), "Record Separator" (0x1E) or "Unit Separator" (0x1F)
Is there a reason why nobody uses these? Did someone work out back in the 90s they were pure evil and we've just never used them since?
Those codes were originally for just such a purpose, but as others point out there was a bootstrapping problem. At this point, if Excel doesn’t support it, it’s not going to gain traction.
About 10 years ago I had to use those for a financial system integration. I was getting files that had been created on a mainframe, and whoever wrote it originally had the foresight to use those characters. Probably because they were based out of EMEA and understood that commas weren’t useful across national borders.
When I was working as a forensic data analyst, I felt pretty much the same. If you request CSV in discovery, there's no telling what you'll get. I mean, the data may come from custom COBOL, and then get reviewed by someone using Excel.
So yes, TSV. However, I've seen TSV with spurious tabs :(
Sometimes I ended up pushing for |-delimited data. Or even fixed-width format :)
But more likely is twisted creativity. It seems that some businesses are still using ancient systems, based on COBOL, AS/400, etc. There's resistance to changing legacy code. So when business changes require additional data fields, fields sometimes get subdivided. So a field that originally contained stuff like |foo| now contains stuff like |"foo","bar,baz"| or whatever. That works, because there's nothing like CSV in the data system. But when someone tries a CSV export, you get garbage.
Newlines in the middle of a quoted field will cause problems for a lot of tools. And Python's csv.DictReader gives an error when a delimited file has too few fields.
I'd rather have a proper text format which I can inspect without a highly specialized tool. In 50 or 500 years it will be hard to hunt down the right tools to open an SQLite file, build SQLite from sources (if they still exist), or reverse-engineer the file format. For a text file you only need to reverse-engineer the ASCII encoding (or maybe UTF-8).
What about hdf5? I'm starting to use it as an in-memory, parsed cache representation for data stored in like a plaintext file document database. With python's PyTables and visidata acts as the independent data explorer app.
I like HDF5 because it's compatible with everything, but it's a bit more difficult to get started with than other modern formats. Partly this is due to design by committee including everything, and the APIs follow suit. With some more modern APIs I think it could come back as an archival format.
Hdf5 files are good if the data is write once, and numeric unless things have changed over the last fives years. From my recollection, you can’t append data so you have to rewrite the whole table and text fields are fixed width.
Heh I was thinking that > 1TiB of data in an sqlite db is a bad idea :).
How do you process that? The restrictions I had in my mind come from that it's infeasible to concurrently process a large dataset in mapreduce/bigquery style.
There are many different concurrence modules for sqlite. I can't see why you would have any problems with what you describe.
The systems I work with use it for backup data. We have many readers and writes. Some of those export a iscsi daemon that represents a block device from the backup that is then booted form.
Reminds me I have to extract data from an 9x day windows application. It's a jetdb that refuses to load in the first viewers I could find. Made me wish it was sqlite (although it didn't exist at the time..)
Well, my personal rule is to never touch csv with excel, because depending on the locales, most of the time excel breaks something in the file. (Of course, in theory I might make a flawless data type mapping when importing the file to excel, but unfortunately that happening is quite rare...)
Yup, see no reason why not. This is answered in the post:
> Any application state that can be recorded in a pile-of-files can also be recorded in an SQLite database with a simple key/value schema like this:
CREATE TABLE files(filename TEXT PRIMARY KEY, content BLOB);
> If the content is compressed, then such an SQLite Archive database is the same size (±1%) as an equivalent ZIP archive, and it has the advantage of being able to update individual "files" without rewriting the entire document.
Is this really a good idea though? I thought it was generally preferred practice to store large binary files outside of the database. Otherwise the database file will end up growing pretty quickly.
That's your call. If you're going to be storing 100gb of images then put them somewhere else, but this post is about using SQLite as a file format so storing binary files inside is not a problem.
We just transitioned our tiled images from using a directory structure to SQLite.
Having a single file per very large image (for mobile) makes transferring them to the phone over USB around ten times as fast. I wish I’d done it years ago.
Creating huge files is usually a bad idea. It does not matter if they are a sequence of lines of characters, a gziped collecion of XML data, a binary format that requires 6000 pages of documentation, or a SQLite database.
If you can spread your data among many files, you probably should. Not everybody can.
Storing large objects in database rows impacts performance and scalability but this shouldn't be a problem unless your files are extraordinarily large.
I don't understand these naysayers. I'm not trying to be mean here, but is there anything more to that than an old guy complaining about how it was awesome in his time and age, and how we get everything wrong nowadays? I'm genuinely asking - are astronauts talking about space programs similar to actors and celebrities taking about moral or political issues? I.e. just famous but not so smart people?
I disagree somewhat with what this astronaut is saying, but generally speaking I think astronauts are supposed to be quite intelligent, especially about issues related to space. I was under the impression that each of them had excellent skills and knowledge in at least one area that benefits their missions and of course strong understanding of space-related things.
So, to answer your question I don't think it's the case that it's similar to celebrities talking about moral and political issues in any way. I assume that he's pretty well informed but just has a totally different view that's less forward-thinking than others of his astronaut brethren.
They're supposed to be quite intelligent about a very specific scenario: operating a specialized vehicle in launch, low/zero gravity, and landing. I wouldn't look to them for understanding or insight into the geopolitical or economic role their missions might be a part of. When listening to experts it's always very important to remember precisely what their expertise happens to be.
Astronauts also have first-hand knowledge about the risks of sending people into space, and have had friends that died or almost died on space missions. So they have a much more concrete concept of the cost-benefit tradeoffs of space travel than the rest of us.
Okay, but even if I concede that point, that doesn't translate into a strong strategic view of the value of initiatives. To say otherwise is like saying a soldier that's been in battle has the same strategic view of things as a general in overall command. The soldier is more informed than the average person, but far from an expert level knowledge of the big picture.
And that may be besides the point: It seem to me this astronaut didn't make make a cogent argument from the perspective of cost-benefit tradeoffs and risk of human lives. Instead he raised vague criticisms: "It's ridiculous" and "what's the imperative... I don't think the public is that interested"
In fact available data directly refutes this astronaut's view: at least one survey from a few years ago found widespread support (about 75%) for a manned mission [0]. As of this year interest has declined somewhat [1], but still 63% rate mars as important or higher.
{kind=link}
https://archive.org/details/malwaremuseum